
Published

About the Author

Justin Knash
Chief Technology Officer at X-Centric
As CTO at X-Centric IT Solutions, Justin leads cloud, security, and infrastructure practice with over 20 years of technology expertise.
TL; DR
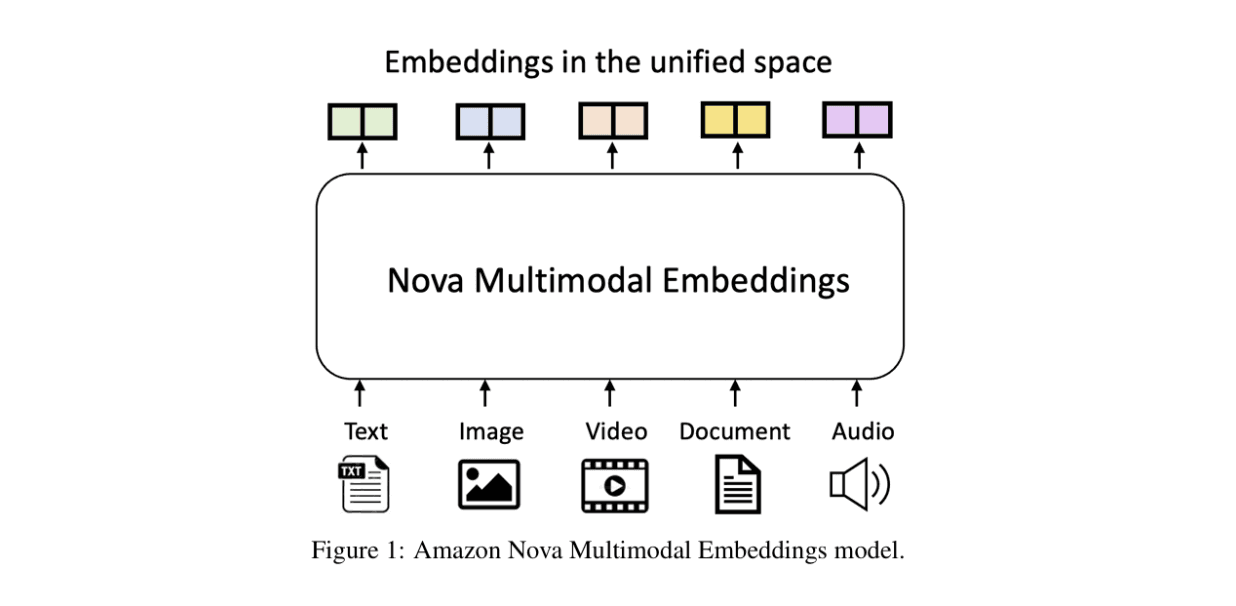
Amazon’s launch of Nova Multimodal Embeddings signals a milestone for enterprise AI. Traditional text-only Retrieval-Augmented Generation (RAG) pipelines rely on a single type of AI model, a method that doesn’t capture the data reality of industries where insights reside in images, audio, video, and sensor streams.
Nova unifies these modalities into a single embedding space, enabling true multimodal retrieval and reasoning. The shift reshapes how enterprises store, govern, and extract value from their data. This article explains the changes introduced by Nova and how leaders can prepare their teams and infrastructure for the multimodal era.
Source: Amazon
Read on to see what it means for your AI roadmap and your competitive edge.
Introduction
When Amazon released Nova Multimodal Embeddings on October 28, 2025, many observers called it the start of a new era for enterprise retrieval as it marks the beginning of a significant shift.
Other tech vendors also provide multimodal RAGs, such as Google Vertex Multimodal Embeddings, Cohere Embed 4, and Twelve Labs Marengo 2.7. However, token constraints restrict their ability to handle long-form enterprise content. Plus, Nova by Amazon supports retrieval across five data sources, i.e., Text, Image, Document, Video, and Audio.
For industries where insight already spans text, images, sensor logs, machine inspections, and field recordings, multimodal retrieval can materially strengthen outcomes.
For others, text-only RAG remains the simplest and most reliable option.
The strategic question is whether the value it creates is worth the additional complexity, governance requirements, cost, and operational oversight.
Why Single Model RAG Is Reaching Its Natural Limits
Text-only RAG has been the dominant pattern because it is simple, governable, and cost-efficient. It continues to perform well in text-heavy environments such as legal workflows, policy libraries, call center transcripts, HR knowledge bases, and general corporate documentation.
However, many industries now operate in environments where meaningful signals hardly ever live in text alone.
Constraints of Single Model Retrieval
1. Unstructured data growth.
Manufacturing lines generate defect images and operator recordings. Pharma laboratories capture video of procedures and instrument logs. Transportation fleets generate camera footage, telematics data, and driver commentary. Treating each modality separately limits the ability to correlate events and surface early indicators.
2. Loss of high-value context.
A text-only pipeline can retrieve the written defect description while ignoring the video that shows the mechanical cause. It can read a driver’s note but misses the sensor audio anomaly that preceded it. This weakens precision in investigations, compliance, and quality control.
3. Fragmentation and cost.
Most enterprises that support several modalities have stitched together separate pipelines, each with its own embedding model, storage pattern, and lifecycle. This increases spending and complicates governance, monitoring, and versioning.
4. Competitive exposure.
Competitors who utilize multimodal retrieval for the right use cases will identify issues more quickly and uncover patterns earlier. This can influence warranty claims, safety outcomes, time to compliance, and customer experience.
Even with these pressures, multimodal retrieval only creates an advantage when the use case truly benefits from integrated signals. This is the nuance many organizations miss.
What Nova Actually Changes
Nova brings a unified embedding layer for five input types: text, documents, images, video, and audio.
In practical terms, this means enterprises can store and search multiple content types within a single semantic space, rather than maintaining separate pipelines.
Important Capabilities of Amazon Nova
1. Unified retrieval.
A single query can return relevant text, video frames, audio slices, or extracted images. This broadens context and reduces blind spots.
2. Simplified architecture.
Fewer embedding models mean fewer moving parts. This can reduce overhead, although teams still require robust ingestion workflows, effective chunking strategies, and stringent quality controls.
3. Operational flexibility.
Nova supports synchronous and asynchronous modes, which helps teams balance speed and cost for video or audio-heavy ingestion workloads.
4. Better alignment with agentic workflows.
Multimodal retrieval enhances agent logic, as agents can reference richer signals during planning, review, and verification tasks.
Despite the benefits, adoption of multimodal RAG systems needs oversight.
Reality Check for Multi-modal Retrieval Augmented Generation
A unified embedding model does not eliminate the need for strong governance. Enterprises still need:
Modality quality scoring
Fallback paths when one modality is unreliable
Cross-modal relevance validation
Retrieval confidence thresholds
Routing rules
Storage and lifecycle controls
Avoidance of embedding drift
Multimodal does not make retrieval easier. It makes retrieval richer, which increases both opportunity and risk.
Where Multimodal RAG Is Not the Right Answer
Multimodal RAG is not universally required. It is not a drop-in upgrade for every workload. It provides meaningful value only when the problems being solved rely on multimodal signals.
Use cases where multimodal is probably unnecessary
Contracts, policies, internal documentation
Corporate communications and HR knowledge bases
ERP, CRM, and ticketing data
Pure text financial or audit workflows
Policy question answering and help desk scenarios.
In these contexts, text-only RAG offers better performance, lower cost, and higher predictability.
Risks of Multimodal Retrieval Leaders Must Account for
Introducing multimodal retrieval increases several forms of operational and governance risk.
1. Higher hallucination risk
When embeddings blend video, audio, and text incorrectly, the model may infer relationships that are not meaningful or relevant. Poorly chunked video, noisy audio, or irrelevant frames can distort retrieval quality.
2. Rising cost and storage requirements
Video and audio ingestion significantly increase storage and embedding costs. A cost governance model is essential for sustainable adoption.
3. More complex monitoring
Multimodal signals require additional health checks, error handling, and quality scoring. These must be designed upfront, not added later under pressure.
4. Integration gaps with existing cloud search stacks
Enterprises often rely on Azure AI Search, AWS Kendra, or Google Vertex AI Search. Nova must integrate into these patterns rather than replace them outright.
5. Fallback logic is mandatory
A mature design must revert to text-only retrieval when other modalities do not meet quality thresholds. Otherwise, responses degrade unpredictably.
Where Multimodal RAG Creates Real Value
Despite the risks, there are domains where multimodal retrieval is a competitive advantage rather than an experiment.
Manufacturing
Faster root cause analysis by linking images, operator notes, and sensor audio
More consistent quality control
Stronger warranty defense through unified evidence
Pharma and Life Sciences
Unified access to lab videos, instrument logs, and documentation
Better traceability for compliance
Cross-modal retrieval for trial monitoring
Transportation, Logistics, and Fleet Operations
Combined retrieval of dash-cam video, telematics, driver notes, and incident logs
Earlier detection of anomalies and safety issues
More accurate training material for drivers and operators
These are domains where multimodal retrieval maps directly to operational and financial impact.
How to Prepare for Multimodal RAGs
Leaders should avoid rebuilding their entire retrieval pipeline. A staged, pragmatic approach is the safest path.
1. Start with a modality inventory
Identify which modalities are already being captured and where they matter to business decisions.
2. Pilot high-ROI modality pairs
Examples include text and an image for defect analysis or video and text for training and compliance.
3. Integrate governance from the start
Include ownership, quality thresholds, lifecycle policies, and auditability.
4. Maintain optionality
Build architectures that can support one unified model, but do not depend on it for every workload. Preserve the ability to run text-only retrieval where it is still optimal.
5. Measure uplift carefully
Success should be defined through improvements in cycle time, accuracy, safety outcomes, or compliance. Do not measure success by the number of modalities included.
Takeaway
Nova Multimodal Embeddings represent a meaningful advancement. They do not make text-only RAG obsolete, and they do not make multimodal retrieval a default requirement. What they do offer is a new competitive advantage for industries where data has already outgrown text-only architectures.
The most mature enterprises will take a measured approach. They will match modality to business value and build retrieval strategies that balance opportunity with operational limitations.
Related Blogs


Kelli Tarala
4
min read
Cybersecurity Risk Management Guide for Executives
Discover how executives can turn cybersecurity risk management into a strategic advantage by aligning risk visibility, resilience, and business priorities.

Justin Knash
5
min read
Decommission Hybrid Exchange: CISA & NSA Guidance
CISA and NSA guidance makes a strong case to decommission Hybrid Exchange—security, compliance, and business alignment now demand it.

Kelli Tarala
5
min read
A Playbook for High-Trust Cybersecurity Culture
Want a stronger cybersecurity culture? Start here. Simple, 8 actionable ways to embed cybersecurity into leadership, habits, and daily workflows.
© 2026 X-Centric IT Solutions. All Rights Reserved